端侧AI使用指南

1 高通AI套件
支持处理器:
- CPU
- GPU
- NPU
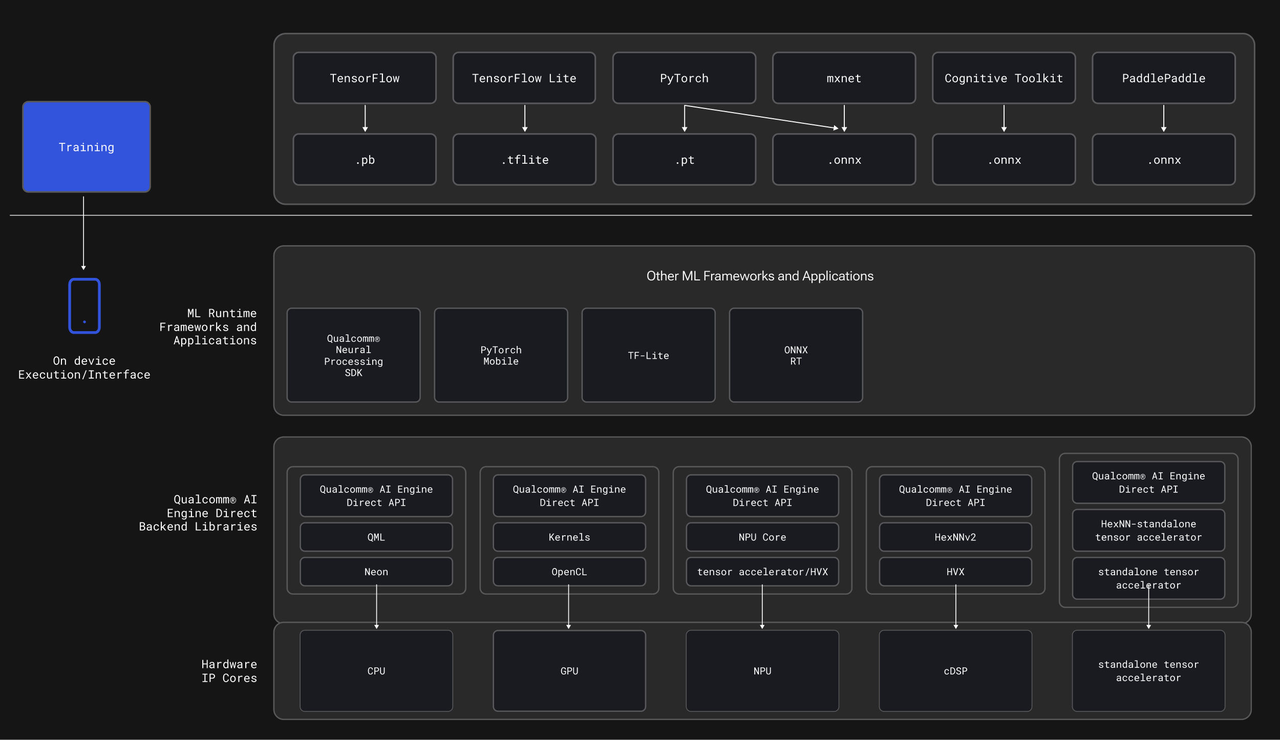
Qualcomm (®) AI Engine Direct SDK 为 AI 开发提供了底层统一的 API。开发人员可以更进一步贴近芯片设计,在 Qualcomm (®) AI 加速器上提高其 AI 模型的性能:Qualcomm (®) Kryo™ CPU、Qualcomm (®) Adreno™ GPU 和 Qualcomm (®) Hexagon™ NPU。
可以使用 SDK 来定位特定的加速器,也可以从 TensorFlow Lite 或 ONNX 运行时委派工作负载以直接访问Hexagon NPU
HTP:具有融合 AI 加速器架构的 Hexagon 处理器 NPU;cDSP:不具有融合 AI 加速器架构的 Hexagon 处理器 NPU;HTA:传统的独立张量加速器
1.1 Qualcomm® AI Hub (编译+性能分析+推理能力分析)
https://aihub.qualcomm.com/
https://aihub.qualcomm.com/get-started#postinstall
https://app.aihub.qualcomm.com/account/ 获取自己的账号AI Token
注:此处编译专门指对模型进行裁剪和优化的过程,训练需要使用高性能设备来进行。
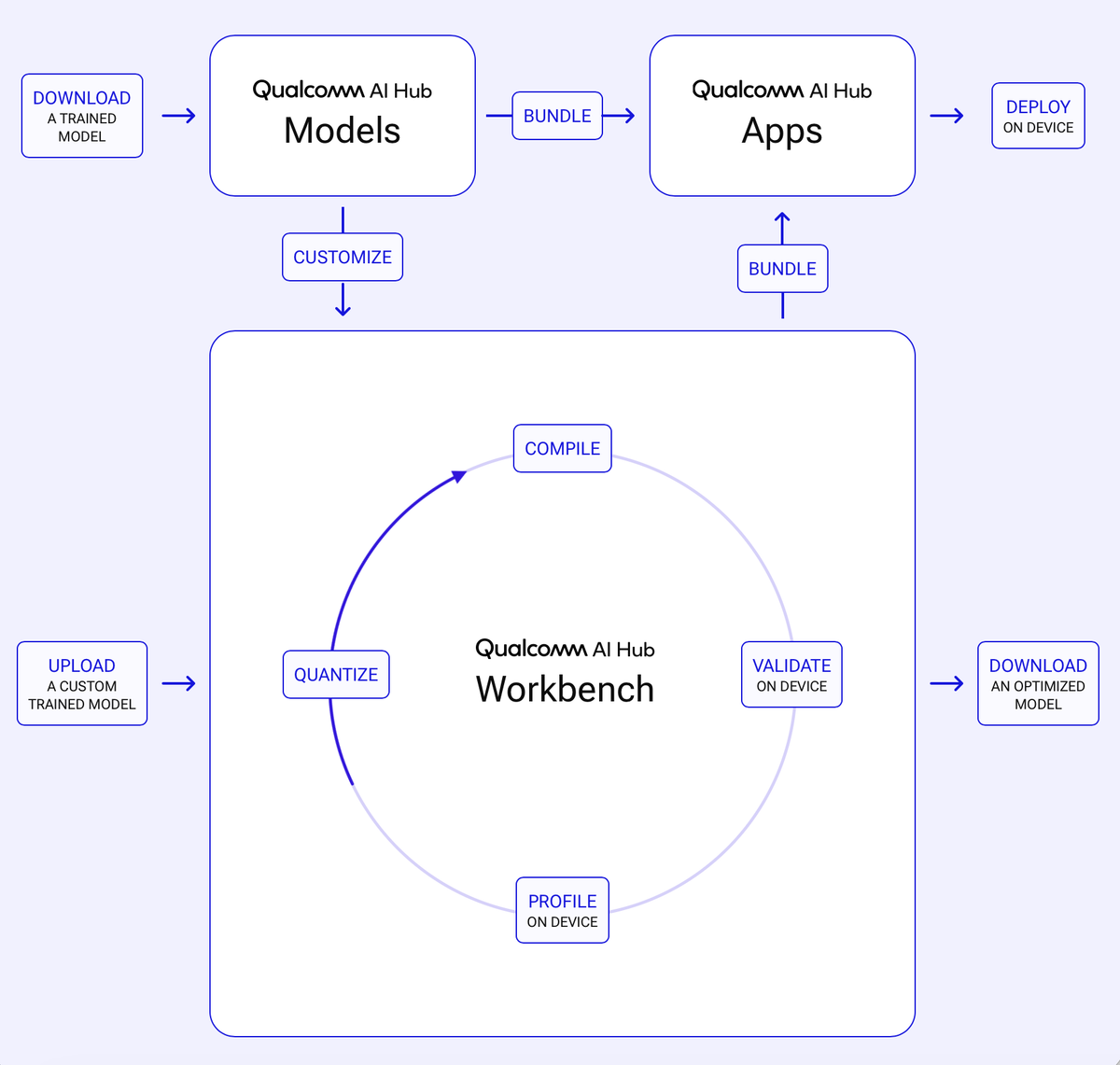
高通Qualcomm AI Hub提供了一个简化部署图像、音频和语音应用的 AI 模型到端侧设备的过程。开发者可以在几分钟内在云端托管的Qualcomm平台设备上优化、验证和部署您自己的 AI 模型。
- 优化了模型转换。自动模型转换 PyTorch或者ONNX实现高效的设备部署TensorFlow Lite, ONNX Runtime,, 或者 Qualcomm AI Engine Direct ,生成的模型针对在 CPU、GPU 或 NPU 上部署进行了优化。
- Qualcomm® AI Hub Models。100多个优化的 AI 模型集合,涵盖视觉、语音、音频和文本应用,可在几分钟内部署到搭载骁龙®和Qualcomm平台的设备上。完全开源可在GitHub和Hugging Face查阅。
- 真实设备上运行。几分钟内即可在云端Qualcomm平台设备上运行模型。只需几行代码即可运行性能分析和设备推理。
1.1.1 安装环境
The Qualcomm AI Hub library for optimization, profiling, and validation can be installed via PyPI. We recommend using Miniconda to manage your python versions and environments. To install, run the following command in your terminal. We recommend a Python version >= 3.8 and <= 3.10.
pip3 install qai-hub
Sign in to Qualcomm AI Hub with your Qualcomm® ID. After signing in, navigate to [your Qualcomm ID] → Settings → API Token. This should provide an API token that you can use to configure your client.
qai-hub configure --api_token API_TOKEN
Once configured, you can check that your API token is installed correctly by fetching a list of available devices with the following command:
qai-hub list-devices
+-------------------------------+------------+----------+---------+---------------------------------------------+---------------------------------------------------------+
| Device | OS | Vendor | Type | Chipset | CLI Invocation |
+-------------------------------+------------+----------+---------+---------------------------------------------+---------------------------------------------------------+
| Google Pixel 3 (Family) | Android 10 | Google | Phone | qualcomm-snapdragon-845, sdm845 | --device "Google Pixel 3 (Family)" --device-os 10 |
| Xiaomi 12 (Family) | Android 12 | Xiaomi | Phone | qualcomm-snapdragon-8gen1, sm8450 | --device "Xiaomi 12 (Family)" --device-os 12 |
| Xiaomi 12 | Android 12 | Xiaomi | Phone | qualcomm-snapdragon-8gen1, sm8450 | --device "Xiaomi 12" --device-os 12 |
| Xiaomi 12 Pro | Android 12 | Xiaomi | Phone | qualcomm-snapdragon-8gen1, sm8450 | --device "Xiaomi 12 Pro" --device-os 12 |
| Samsung Galaxy S24 (Family) | Android 14 | Samsung | Phone | qualcomm-snapdragon-8gen3, sm8650 | --device "Samsung Galaxy S24 (Family)" --device-os 14 |
| Samsung Galaxy S24 | Android 14 | Samsung | Phone | qualcomm-snapdragon-8gen3, sm8650 | --device "Samsung Galaxy S24" --device-os 14 |
| Samsung Galaxy S24 Ultra | Android 14 | Samsung | Phone | qualcomm-snapdragon-8gen3, sm8650 | --device "Samsung Galaxy S24 Ultra" --device-os 14 |
| Samsung Galaxy S24+ | Android 14 | Samsung | Phone | qualcomm-snapdragon-8gen3, sm8650 | --device "Samsung Galaxy S24+" --device-os 14 |
| Snapdragon 8 Elite QRD | Android 15 | Qualcomm | Phone | qualcomm-snapdragon-8-elite, sm8750 | --device "Snapdragon 8 Elite QRD" --device-os 15 |
| SA8295P ADP | Android 14 | Qualcomm | Auto | qualcomm-sa8295p | --device "SA8295P ADP" --device-os 14 |
| SA8775P ADP | Android 14 | Qualcomm | Auto | qualcomm-sa8775p | --device "SA8775P ADP" --device-os 14 |
| SA7255P ADP | Android 14 | Qualcomm | Auto | qualcomm-sa7255p | --device "SA7255P ADP" --device-os 14 |
+-------------------------------+------------+----------+---------+---------------------------------------------+---------------------------------------------------------+
1.1.2 在云端设备运行第一个PyTorch模型
设置好Qualcomm AI Hub环境后,下一步是在云托管设备上优化、验证和部署 PyTorch 模型。此示例需要一些额外的依赖项,可以使用以下命令安装:
pip3 install "qai-hub[torch]"
现在,可以请求对 MobileNet v2 网络进行自动性能分析。此示例在真实托管设备上编译并分析模型:
支持:
- 移动端
- 计算机
- 汽车
- 物联网
import qai_hub as hub
import torch
from torchvision.models import mobilenet_v2
import requests
import numpy as np
from PIL import Image
# Using pre-trained MobileNet
torch_model = mobilenet_v2(pretrained=True)
torch_model.eval()
# Step 1: Trace model
input_shape = (1, 3, 224, 224)
example_input = torch.rand(input_shape)
traced_torch_model = torch.jit.trace(torch_model, example_input)
# Step 2: Compile model
compile_job = hub.submit_compile_job(
model=traced_torch_model,
device=hub.Device("Samsung Galaxy S24 (Family)"),
input_specs=dict(image=input_shape),
)
# Step 3: Profile on cloud-hosted device
target_model = compile_job.get_target_model()
profile_job = hub.submit_profile_job(
model=target_model,
device=hub.Device("Samsung Galaxy S24 (Family)"),
)
# Step 4: Run inference on cloud-hosted device
sample_image_url = (
"https://qaihub-public-assets.s3.us-west-2.amazonaws.com/apidoc/input_image1.jpg"
)
response = requests.get(sample_image_url, stream=True)
response.raw.decode_content = True
image = Image.open(response.raw).resize((224, 224))
input_array = np.expand_dims(
np.transpose(np.array(image, dtype=np.float32) / 255.0, (2, 0, 1)), axis=0
)
# Run inference using the on-device model on the input image
inference_job = hub.submit_inference_job(
model=target_model,
device=hub.Device("Samsung Galaxy S24 (Family)"),
inputs=dict(image=[input_array]),
)
on_device_output = inference_job.download_output_data()
# Step 5: Post-processing the on-device output
output_name = list(on_device_output.keys())[0]
out = on_device_output[output_name][0]
on_device_probabilities = np.exp(out) / np.sum(np.exp(out), axis=1)
# Read the class labels for imagenet
sample_classes = "https://qaihub-public-assets.s3.us-west-2.amazonaws.com/apidoc/imagenet_classes.txt"
response = requests.get(sample_classes, stream=True)
response.raw.decode_content = True
categories = [str(s.strip()) for s in response.raw]
# Print top five predictions for the on-device model
print("Top-5 On-Device predictions:")
top5_classes = np.argsort(on_device_probabilities[0], axis=0)[-5:]
for c in reversed(top5_classes):
print(f"{c} {categories[c]:20s} {on_device_probabilities[0][c]:>6.1%}")
# Step 6: Download model
target_model = compile_job.get_target_model()
target_model.download("mobilenet_v2.tflite")
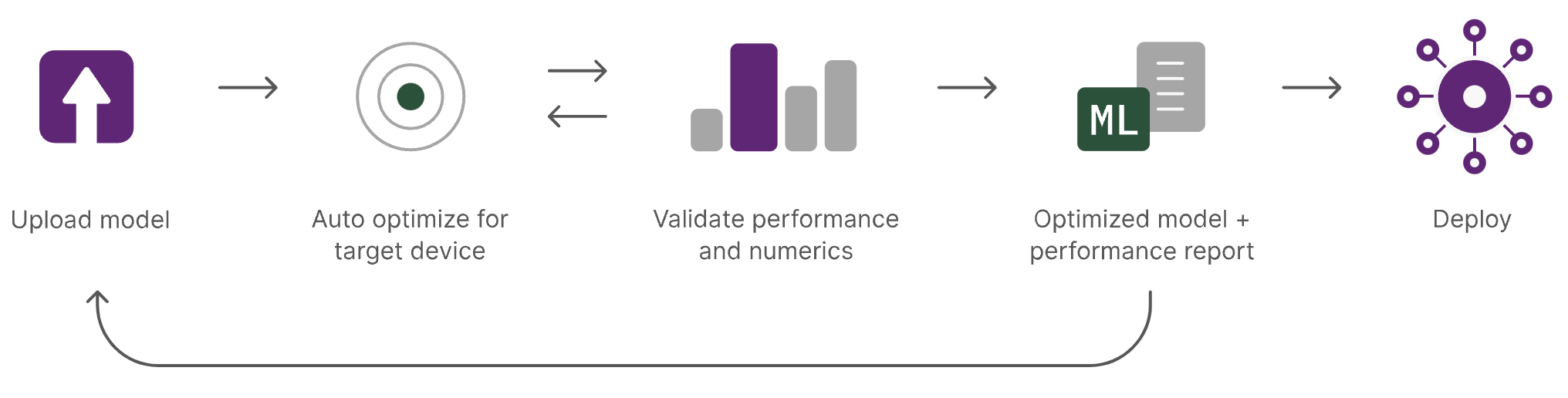
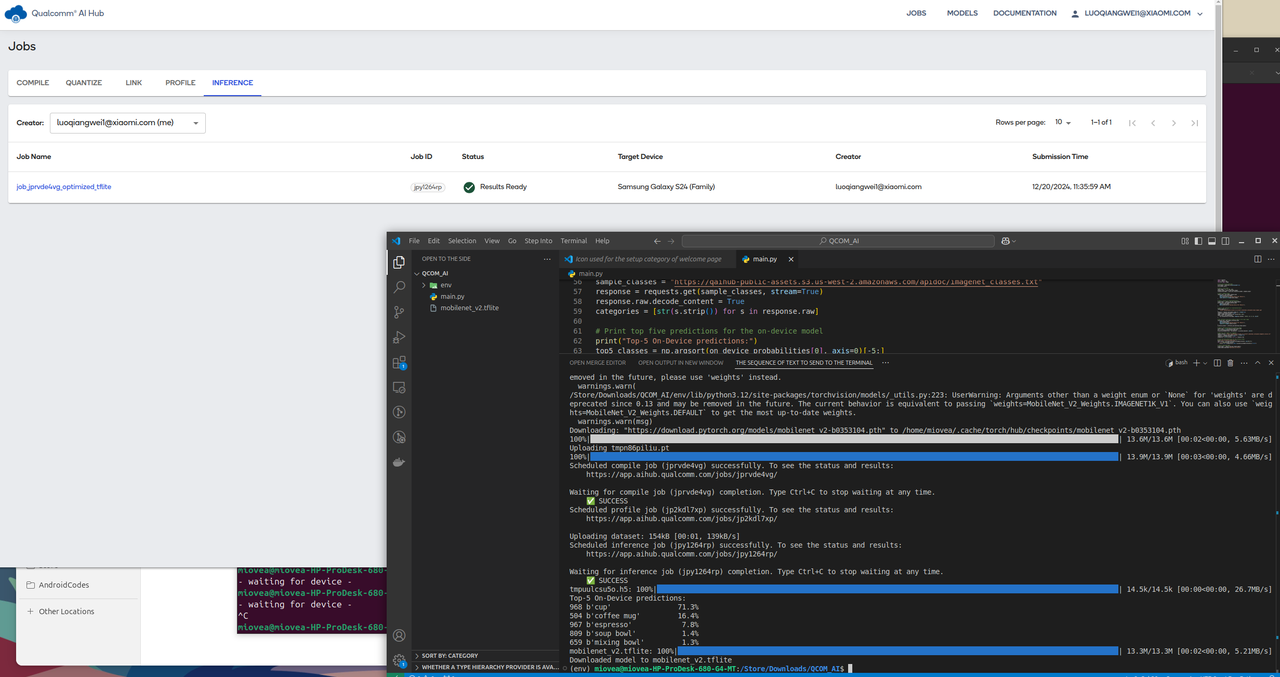
提交云端编译运行后,最后会产生一个编译后的模型文件(目的是为了优化、裁剪到适合高通机型运行的模型),同时也会显示推理的结果。
提交云端后,QCOM AI HUB会产生三个任务:
- 编译任务
- 性能分析任务
- 模型推理任务
其中性能分析任务和模型推理任务是同步进行的
运行模型的性能数据
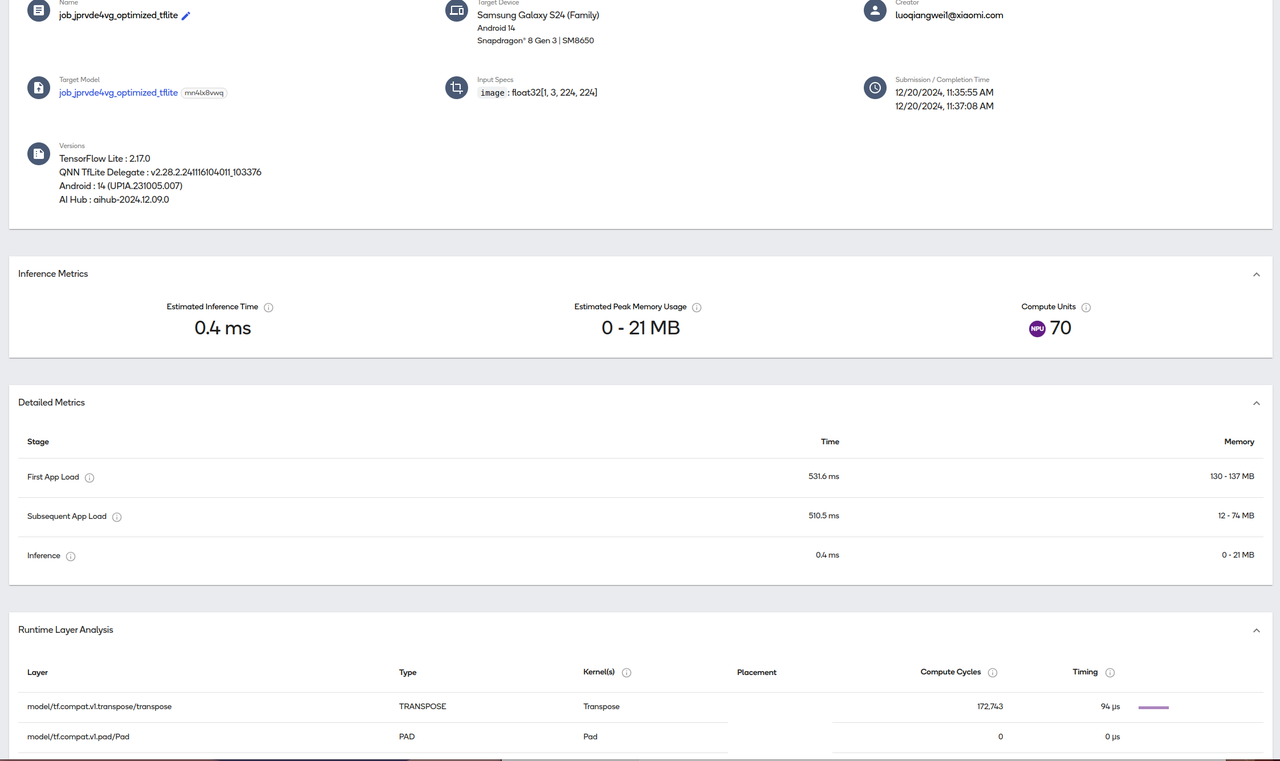
云端运行识别图片的结果(图片是一杯咖啡)
https://app.aihub.qualcomm.com/docs/hub/profile_examples.html#profile-examples
1.1.3 Qualcomm AI HUB提供大量开源模型
Qualcomm AI Hub模型是针对性能进行了优化的先进机器学习模型的集合,可直接部署在Qualcomm平台设备上。您可以探索针对视觉、语音、文本和生成式 AI 应用的设备部署而优化的模型。所有模型均附带开源配方GitHub和Hugging Face。
1.1.4 实时自拍分割部署到设备的例子
https://ai.google.dev/edge/mediapipe/solutions/vision/image_segmenter?hl=zh-cn
首先,安装 Qualcomm AI Hub Models python包
pip3 install "qai-hub-models[ffnet_40s]"
运行本地基于 PyTorch 的 CLI 演示,使用一些示例输入验证设备外模型。
python -m qai_hub_models.models.ffnet_40s.demo

一旦通过设备外验证,您就可以在几分钟内在托管的Qualcomm 平台设备上运行该模型。
python -m qai_hub_models.models.ffnet_40s.export
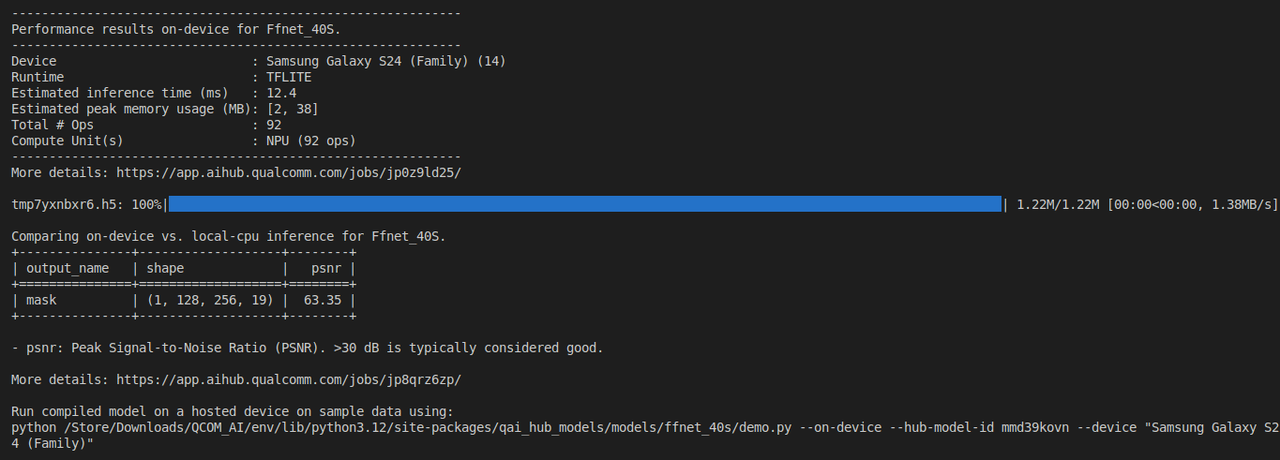
上述脚本优化了模型以在设备上执行,在云端托管的 Qualcomm平台设备上对模型进行分析,在设备上运行模型,并比较基于本地 CPU 的 PyTorch 运行和设备运行之间的准确性。最后,您可以运行一个完整的演示,并在设备上运行推理。
python -m qai_hub_models.models.ffnet_40s.demo --on-device
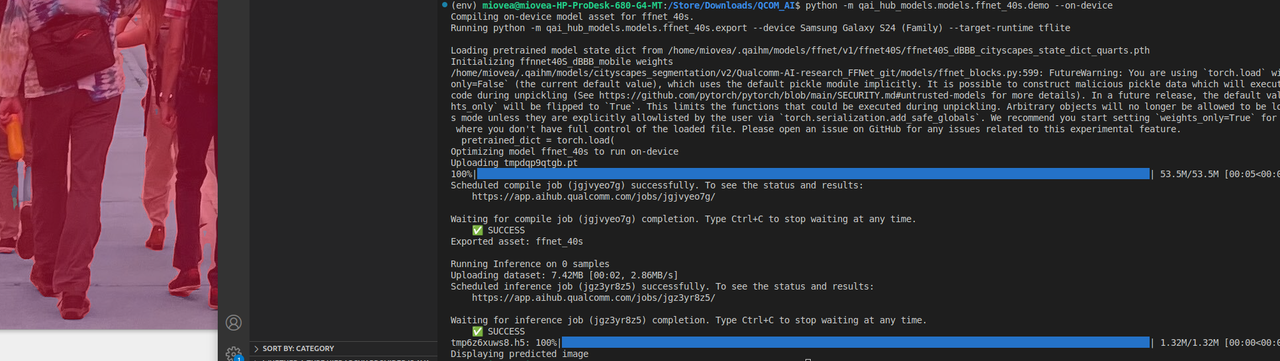
1.2 高通端侧AI部署(CPU+GPU+NPU)SOC平台依赖解决方案
https://github.com/quic/ai-hub-apps?tab=readme-ov-file
1.2.1 模型编译:配置本地Python环境
安装qai-hub-models
mkdir qai-hub-models
cd qai-hub-models
python3 -m venv llm_on_genie_venv
source llm_on_genie_venv/bin/activate
pip install -U "qai_hub_models[qwen2_7b_instruct_quantized]"
mkdir genie_bundle
1.2.2 下载和生成兼容Genie的QNN二进制文件
For Snapdragon 8 Gen 3, please use --chipset qualcomm-snapdragon-8gen3
Note: For older devices, you may need to adjust the context length using --context-length <context-length>.
python -m qai_hub_models.models.qwen2_7b_instruct_quantized.export --chipset qualcomm-snapdragon-8-elite --skip-inferencing --skip-profiling --output-dir genie_bundle
cp /home/miovea/.qaihm/models/qwen2_7b_instruct_quantized/v2/snapdragon_8_elite/models/* genie_bundle/
8650
python -m qai_hub_models.models.qwen2_7b_instruct_quantized.export --chipset qualcomm-snapdragon-8gen3 --skip-inferencing --skip-profiling --output-dir genie_bundle
cp /home/miovea/.qaihm/models/qwen2_7b_instruct_quantized/v2/snapdragon_8_elite/models/* genie_bundle/
1.2.3 安装QNN SDK
https://qpm.qualcomm.com/#/main/tools/details/qualcomm_ai_engine_direct
https://qpm.qualcomm.com/#/main/tools/details/QPM3
- 先安装QPM3
- 然后再通过QPM3提取Qualcomm® AI Engine Direct SDK
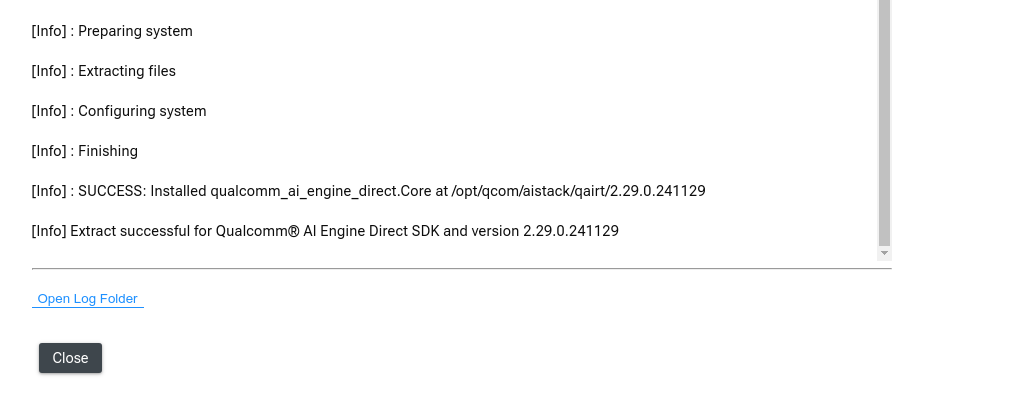
vim ~/.bashrc
# 添加配置信息
export QNN_SDK_ROOT=/opt/qcom/aistack/qairt/2.29.0.241129
1.2.4 准备进行Genie配置
1.2.4.1 HTP后端配置
下载ai hub apps仓库
git clone https://github.com/quic/ai-hub-apps.git
复制HTP配置模版:
cp ai-hub-apps/tutorials/llm_on_genie/configs/htp/htp_backend_ext_config.json.template genie_bundle/htp_backend_ext_config.json
修改genie_bundle/htp_backend_ext_config.json文件中的soc_model和dsp_arch配置信息,根据下面的列表进行配置。
| Generation | soc_model | dsp_arch |
|---|---|---|
| Snapdragon® Gen 2 | 43 | v73 |
| Snapdragon® Gen 3 | 57 | v75 |
| Snapdragon® 8 Elite | 69 | v79 |
| Snapdragon® X Elite | 60 | v73 |
1.2.4.2 Tokenizer
https://huggingface.co/qualcomm/Qwen2-7B-Instruct
https://huggingface.co/Qwen/Qwen2-7B-Instruct/tree/main
下载tokenizer.json到genie_bundle目录
1.2.4.3 Genie配置
cp ai-hub-apps/tutorials/llm_on_genie/configs/genie/qwen2_7b_instruct_quantized.json genie_bundle/genie_config.json
1.2.5 复制Genie二进制文件
# For 8 Gen 3
cp $QNN_SDK_ROOT/lib/hexagon-v75/unsigned/* genie_bundle
# For 8 Elite
cp $QNN_SDK_ROOT/lib/hexagon-v79/unsigned/* genie_bundle
# For all devices
cp $QNN_SDK_ROOT/lib/aarch64-android/* genie_bundle
cp $QNN_SDK_ROOT/bin/aarch64-android/genie-t2t-run genie_bundle
1.2.6 在设备上运行LLM
adb push genie_bundle /data/local/tmp
adb shell
cd /data/local/tmp/genie_bundle
export LD_LIBRARY_PATH=$PWD
export ADSP_LIBRARY_PATH="$PWD;/odm/lib/rfsa/adsp;/vendor/lib/rfsa/adsp/;/system/lib/rfsa/adsp;/system/vendor/lib/rfsa/adsp;/dsp"
./genie-t2t-run -c genie_config.json -p "<|begin_of_text|><|start_header_id|>user<|end_header_id|>\n\nWhat is France's capital?<|eot_id|><|start_header_id|>assistant<|end_header_id|>"
但是在小米15上无法跑起来,目前问题还不清楚(通过设置ADSP_LIBRARY_PATH可以解决这个问题)
Using libGenie.so version 1.2.0
[ERROR] "Failed to create device: 1008"
[ERROR] "Device Creation failure"
Failure to initialize model
Failed to create the dialog.
小米14上的错误:
Using libGenie.so version 1.2.0
[INFO] "Using create From Binary"
[INFO] "Allocated total size = 174998016 across 8 buffers"
[ERROR] "Could not create context from binary for context index = 0 : err 5005"
[ERROR] "Create From Binary FAILED!"
Failure to initialize model
Failed to create the dialog.
小米15上的大模型运行结果:

1.3 高通机型App运行大模型的解决方案(CPU+GPU+NPU)
- LIB依赖:
- QNN SDK**(目前似乎有协议问题,无法内置到系统中,只能App开发者引入,或者获取商业授权)**
- /odm/lib/rfsa/adsp
- /vendor/lib/rfsa/adsp/
- /system/lib/rfsa/adsp
- /system/vendor/lib/rfsa/adsp
- /dsp
- 通过高通AI HUB将大模型编译优化成高通QNN使用的文件。
- 在NDK引入并使用这些LIB以获取高通GPU、NPU的硬件支持。
2 Google AI Edge(CPU+GPU)通用解决方案
https://developer.android.com/ai/generativeai?hl=zh-cn
https://ai.google.dev/edge?hl=zh-cn
支持的处理器:
- CPU
- GPU
2.1 Mediapipe框架
https://github.com/google-ai-edge/mediapipe
MediaPipe Solutions 提供了一套库和工具,可让您快速将人工智能 (AI) 和机器学习 (ML) 技术应用于您的应用程序。
3 MTK套件
https://neuropilot.mediatek.com/
https://www.mediatek.com/tek-talk-blogs
https://neuropilot.mediatek.com/resources/public/latest/en/docs/npu_introduction
参考
https://github.com/QingweiJi/PowerNPU
https://www.qualcomm.com/developer/software/qualcomm-ai-engine-direct-sdk
https://www.qualcomm.com/developer/artificial-intelligence#overview
https://www.qualcomm.com/developer/artificial-intelligence#overview
https://github.com/quic/ai-hub-apps/tree/main
AI Core:https://android-developers.googleblog.com/2023/12/a-new-foundation-for-ai-on-android.html
https://github.com/google-gemini/generative-ai-android
https://ai.google.dev/gemini-api/docs/get-started/android_aicore?hl=zh-cn
https://cs.android.com/android/platform/superproject/main/+/main:packages/modules/NeuralNetworks/
QNN