F2FS介绍

一、背景介绍
一个对基于NAND并且具备FTL(闪存转换层)的闪存设备友好的文件系统,该文件系统依赖于FTL来处理写操作。F2FS对FTL的支持,在于一开始就将存储空间划分为若干个大小相同的segment,然后多个segment由section进行管理。F2FS期望section大小与FTL中垃圾收集单元大小相同。
需要注意的是,FTL一般处于具备SCSI/SATA/PCIe/NVMe接口的闪存中。
1.1 FTL的原理
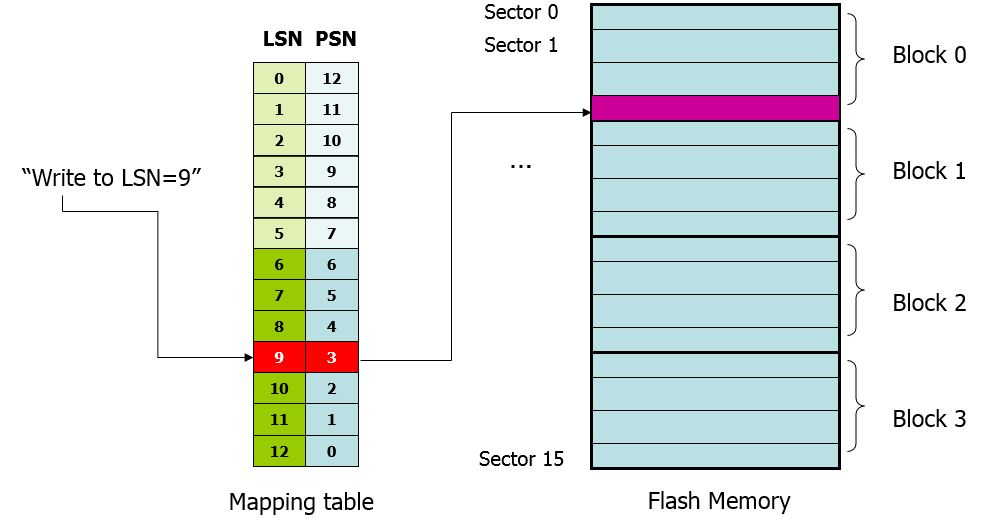
FTL简单来说就是系统维护了一个逻辑Block地址(LBA,logical block addresses )和物理Block地址(PBA, physical block addresses)的对应关系。

这样就不需要操作系统额外针对闪存设备进行额外的优化了,优化由闪存本身内建的微型系统来完成(例如磨损均衡,废块回收等)。
举一个例子,FAT文件系统,它有很大的概率会在数据读写的过程中对同一逻辑地址的存储空间进行操作,如果没有优化操作,对应的NAND颗粒寿命很快就会被消耗殆尽,最后导致整个闪存都无法使用。
通过FTL层,闪存将操作系统的操作的逻辑地址记录在FTL表上,自身根据均衡磨损算法,将数据存储在使用次数较小的区域,然后再将该物理位置记录在表中对应的逻辑地址后面,以此来保证每个NAND颗粒的使用次数尽可能接近(即损耗的情况尽可能相同),以延迟闪存的寿命。
1.2 Log Structured File System —— 日志结构文件系统
- 它主要用于解决传统文件系统随机I/O与顺序I/O性能差异大的问题,日志结构文件系统将所有的更改以日志式的结构连续(顺序I/O)写入磁盘,以此加速文件写入性能。
- 在大内存的设备中,写入性能逐渐变为了文件系统的瓶颈(读取性能可以在内存中做缓存机制提高)
1.2.1 Wandering Tree 问题
当文件的数据块被更新时写到 log 的末尾,该数据块的直接指针也因为数据位置的改变而更改,然后间接指针块也因为直接指针块的更新而更新。按照这种方式,上层的索引结构,如 inode、inode map 以及 checkpoint block 也会递归地更新,这就是所谓的 wandering tree 问题。

1.2.2 Cleaning(GC)开销问题
为了产生新的 log 空闲空间,LFS 需要回收无效的数据块,释放出空闲空间,这一过程称为 Cleaning 过程。Cleaning 过程包含如下操作:
(1) 通过查找 segment 使用情况链表,选择一个 segment;
(2) 通过 segment summary block 识别出选中的 segment 中的所有数据块的父索引结构并载入到内存;
(3) 检查数据及其父索引结构的交叉引用;
(4) 选择有效数据进行转移有效数据。
Cleaning 工作可能会引起难以预料的长延时,因而 LFS 要解决的一个重要问题是对用户隐藏这种延时,并且应当减少需要转移的数据的总量以及快速转移数据。
1.3 F2FS相比传统LFS的优势
1.3.1 解决Wandering Tree问题
引入 Node Address Table (NAT)用于包含所有“node”块的位置,切断数据块更新的递归传播。
下面是一个比较简化的描述。
一般来说,修改了文件数据(由于LFS的特点,文件数据是往后面空闲区域写的,而不是原位),所以需要修改直接索引节点记录的文件数据地址(LFS特性,直接索引节点也是往后面空闲区域写入的,而不是原位),由于直接索引节点的位置发生了变化,所以需要修改相应的间接索引节点记录的直接索引节点的地址(LFS特性,间接索引节点往后写入,而不是原位),最后直到修改完索引表。
采用NAT之后,修改了文件数据,需要修改直接索引节点记录的文件数据地址,这里当直接索引节点更新之后直接修改NAT表记录的索引地址即可,原因在于间接索引节点在F2FS中记录的不再是直接索引节点绝对地址,而是直接索引节点在NAT表项中的相对地址,所以最终可以通过NAT表这种设计方式阻断递归更新问题。
此处的node包含了inode、Direct Node、Indirect Node等

1.3.2 处理Cleaning(GC)开销问题
- 通过multi-head logs将3中文件系统结构hot与cold的数据分离,针对不同的section数据使用不同的GC频率,降低GC消耗
- 支持后台进行cleaning操作
- 引入自适应的空间分配方式分配块
1.3.3 适应存储设备(UFS等硬件)的GC
将每个段(section)的大小和FTL垃圾收集单元大小对齐,后面当F2FS进行GC时,以段(section)为单位进行GC(空出的区域,会以trim指令通知存储设备,让存储设备在合适的时机对无效的FTL区域进行GC,对应的NAND会进行数据混淆),这样存储设备(UFS)在GC时,可以刚好擦除FTL这个区域的数据,总的来说可以减少存储设备(UFS) GC所需的操作(因为UFS等硬件不再需要使用垃圾回收算法空出一个FTL的区域再进行擦除,这个步骤已经由F2FS完成了,所以只需要直接擦除即可)。
1.4 关于trim指令(discard功能)
由于叠瓦式机械硬盘和SSD都带有FTL层来存储逻辑数据位置,实际存储位置和逻辑位置并不相同,当我们格式化分区或者删除文件的时候,只是修改了元数据而已,而这些数据占一个分区或者一个文件大小来说是微乎其微的!其他数据虽然已经都不需要了,可是由于FTL层的存在,存储器只能认为刚才所谓的格式化或删除操作,只是在某个逻辑地址写了了一些数据,其他逻辑地址的数据都还需要,所以存储器并不会清空FTL层数据和实际的存储空间。
当操作系统写入数据到已经使用过的逻辑地址上时,存储器则需要临时去清除这块逻辑地址的空间,然后再存放数据,这样需要花费很长的时间!等到FTL的逻辑地址几乎消耗殆尽后,操作系统有更大的概率将数据写入到已经使用过的逻辑地址上,这也是存储器开始掉速的原因!
trim指令则是通过一种方式,告知存储器现在哪些逻辑地址还在使用,哪些不再使用了,这样存储器就会清除FTL表相关的逻辑地址,它们对应的存储空间也会立刻被混淆处理(防止数据泄露),空闲时再回收,下次存储器就可以直接使用了而无需再临时清除数据后再写入数据。
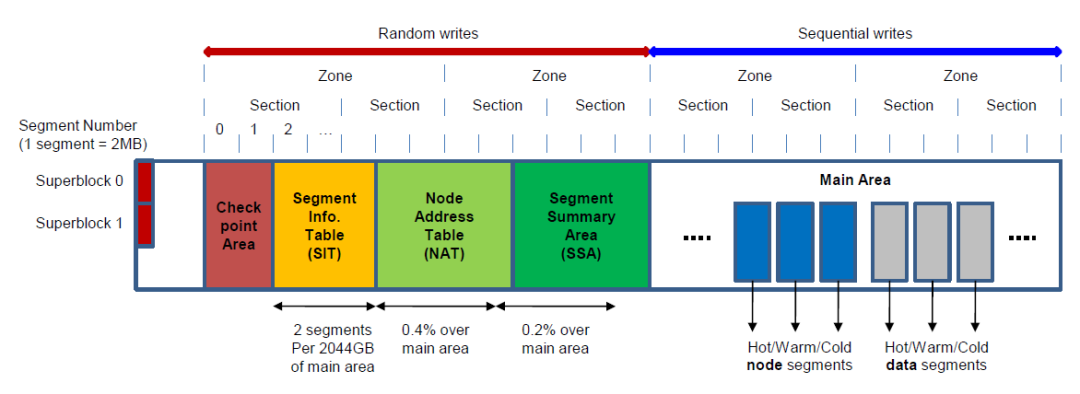
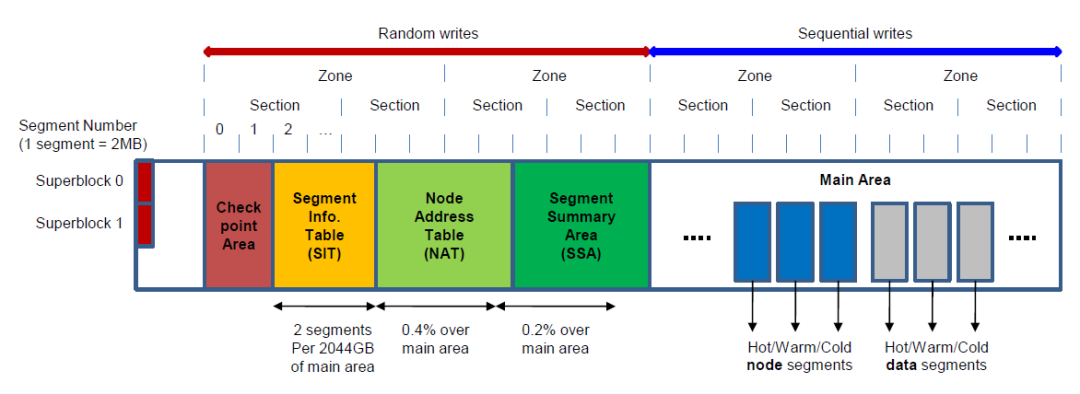
二、磁盘布局
F2FS将整个卷划分为大小为2MB的若干个segment,一个section是由连续的段组成的segment组成的,一个zone包含了若干个section。
在默认情况下,section和zone的大小会设置的一样大,但是也可以通过mkfs工具进行修改。

F2FS将整个卷分为6个区域,所有区域都由多个segment组成(除了superblock)。
为了避免文件系统和闪存之间错位,F2FS将CP的起始地址与段大小对齐。它还通过在SSA区域中保留一些段,将主区域起始地址与区域大小对齐。
1. Superblock(SB)—— 超级块
超级块位于分区开头,它有两个副本防止文件系统彻底损坏。超级块中包含了分区基本信息,还有一些
F2FS的默认参数。
2. Checkpoint (CP) —— 检查点
检查点包括文件系统信息,有效的NAT/SET位图,孤立索引节点列表和当前活跃的segment的摘要信息。
3. Segment Information Table (SIT) —— 段信息表
SIT包含所有主区域块的有效块计数和有效位图。
4. Node Address Table (NAT) —— 节点地址表
NAT是主区域node块的地址表。
5. Segment Summary Area (SSA) —— 段信息摘要区域
SSA包含主区域数据和节点(node)块的所有者信息的条目。
6. Main Area —— 主区域
主区域包含了文件和目录数据以及它们的索引。
三、元数据结构(Metadata)
F2FS使用检查点来维护系统完整性。在挂载时,F2FS首先会尝试通过扫描CP区域来找到最后一个有效的检查点数据(F2FS只是用了CP的两个副本,其中一个副本始终表示最后一个有效数据,这个被称为Shadow Copy机制,不仅CP会使用这个机制,NAT和SIT也会使用)。为了文件系统的一致性,每个CP都指向哪些NAT和SIT的副本是有效的。
四、索引结构(Index)
F2FS有三种类型的阶段,索引节点(inode),直接索引节点(direct node),间接索引节点(indirect node)。
一个索引节点的大小是4KB,它包含923个数据块索引,2个直接节点(direct node)指针,2个间接节点(indirect node)指针和一个双间接节点(double indirect node)指针。
一个直接节点(direct node)块中包含1018个数据块索引,间接节点(indirect node)块包含1018个直接索引节点(direct node)块索引,双间接节点(double indirect node)块包含了1018个间接节点(indirect node)索引。
4 KiB × (923 + 2×1018 + 2×1018^2+ 1018^3) = 4,228,213,756 KiB = 4,129,114.996 MiB = 4,032.338863 GiB = 3.937830921 TiB
所有的节点块都是由NAT映射,意味着每个节点位置由NAT转换。
五、目录结构(Directory)
目录条目(directory entry(dentry))由下面11个字节的数据组成,包含以下信息
| hash | Hash value of the file name |
| ino | Inode number |
| len | The length of file name |
| type | File type such as directory, symlink, etc. |
一个目录块由214个dentry slots和文件名组成。使用位图表示每个dentry是否有效。一个dentry block是4KB大小
Dentry Block (4 K) = bitmap (27 bytes) + reserved (3 bytes) + dentries (11 * 214 bytes) + file name (8 * 214 bytes)
六、默认的块划分
在运行时,F2FS在主区域(Main Area)管理着6个活跃的记录:Hot/Warm/Cold node and Hot/Warm/Cold data.
| Hot node | 目录的direct node使用,因为打开目录、读取目录是最频繁的操作 |
| Warm node | 普通文件的direct node使用 |
| Cold node | indirect node使用,一般而言只有较大的文件才会使用到这个log区域 |
| Hot data | 给目录的数据使用,目录数据记录了当前目录有多少个子文件、子文件夹(small size write) |
| Warm data | 普通文件的数据使用,常规的fwrite/write函数写入的数据都是在这里分配 |
| Cold data | 不频繁修改的数据使用,如多媒体文件(多为只读文件),或者用户指定的只读文件,如GC产生写的数据(gc会挑热度最低的数据) |

关于F2FS数据节点的hot/cold可以在extension_list中看到,还有一部分数据时根据文件后缀来判断是放在hot还是cold区域的。

LFS的两种空间管理方案
- 穿插记录(threaded log) SSR Alloc
- 它会受到随机写入的影响,但是不需要清理过程。
- 复制和压缩(copy-and-compaction) LFS Alloc
- 该方案适合于具有高顺序写入性能的设备,因为空闲的段将被始终用于写入新数据,但是在高负载情况下会受到清理开销的影响。
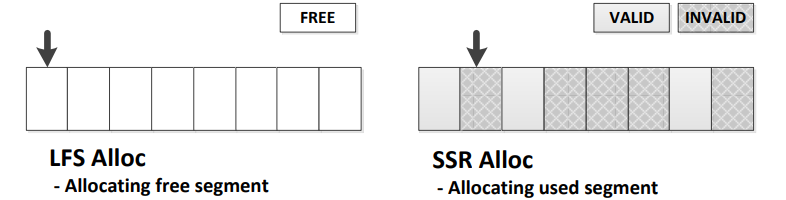
F2FS采用了两种组合的自适应空间分配方案,默认使用复制和压缩,但是会根据文件系统状态(当空间不足时)动态变更为穿插记录方案。
七、清理进程
F2FS分为前台GC和后台GC(后台GC由内核线程完成)。当没有足够的segments完成VFS调用时,会触发主动式的清理操作。
后台GC时,会检查当前系统是否处于空闲且未被挂起的状态。
下图7次后台GC只成功了3次

Greedy算法
F2FS 执行 foreground gc 时采用 Greedy 算法。
为实现 Greedy 算法,F2FS 维护一张记录每一个 section 中有效 block 数的元数据表,执行 gc 操作时,根据这个元数据表找出有效 block 数最少的 n 个 section 作为 victim。
直观地说,Greedy算法能使gc时迁移的有效块数最少,从而开销最小,所以 F2FS 在 foreground gc 时采用 Greedy 算法,最小化应用能感知的延迟。
Cost-Benefit算法
F2FS 在执行 background gc 时采用 Cost-Benefit 算法,主要思想是计算出每个 section 的迁移开销,选在开销最小的 n 个section 作为 victim,开销的计算方法如下:
cost = (1−μ) / 2μ ∗ age
其中,u 代表 valid block 在该 section 中的比例,age 代表该 section 距离最近一次修改的时间;
1-u 是对这个 section 进行 gc 以后能够获得 free block 的数量;
2u 是对这个 section 进行 gc 的开销,读取 Valid block(1个u)然后写入到新的 section (再1个u);
所以(1-u)/ 2u 可以理解为投入产出比。
F2FS 需要在维护的元数据表里,记录每个 section 最后一次被写入的时间,gc 时选择更久没有被修改的section(冷数据)作为 victim。
该策略就是选择投入产出比更高,未修改时间更长的 section 进行 gc,两者相乘数字更大的优先被 gc。
ATGC (Age Threshold based Garbage Collection)算法
为了提高 background gc 的效率,F2FS 引入 ATGC。
ATGC 算法设定 age 阈值,过滤掉部分 old segment,避免他们成为 victim;在做 gc 时,尽量选择与 victim age 相近的 section 作为 target;然后通过 SSR 的方式把 valid block 迁移到target section。这样能带来的好处有:
避免选择young section 作为victim;
SSR避免target中没必要block迁移;
源 section 和目的 section age 相近,能保持冷热的分离效果。
参考资料
https://en.wikipedia.org/wiki/F2FS
https://wiki.archlinux.org/title/F2FS
https://zhuanlan.zhihu.com/p/26944064
https://accelazh.github.io/images/ssd-ftl-bottom-up-p2.pdf https://blog.csdn.net/feelabclihu/article/details/105534143
https://zhuanlan.zhihu.com/p/41358013
https://link.springer.com/content/pdf/10.1007/978-3-030-98467-0_3.pdf
http://lunwen.nangxue.com/html/dianzishangwulunwen/2010/1011/17419.html
https://www.modb.pro/db/157459
https://bynss.com/howto/303800.html
https://docs.freebsd.org/doc/5.4-RELEASE/usr/share/doc/zh_CN.GB2312/books/handbook/quotas.html
https://jaehyek.github.io/2016/12/07/eMMC-UFS-FTL-1/
https://github.com/RiweiPan/F2FS-NOTES/blob/master/F2FS-GC/GC流程介绍.md
https://blog.csdn.net/qq_36059308/article/details/112182002
http://nyx.skku.ac.kr/wp-content/uploads/2019/12/14-F2FS.pdf
http://blog.chinaunix.net/uid-27714502-id-3904206.html
http://fengziran.com/index.php/2021/10/16/论文:an-empirical-study-of-f2fs-on-mobile-devices/
https://www.cxyzjd.com/article/u011649400/94588840
http://blog.chinaunix.net/uid-31417475-id-5756263.html
https://yanhang.me/post/2019-04-20-jffs3/
https://blog.csdn.net/wdy_yx/article/details/42848773
https://cloud.tencent.com/developer/article/1673101
https://xiaomi.f.mioffice.cn/docs/dock4syiXcbg7mBAzWlp1Z7Cuzf