rust语言学习记录

Ruat tools
rustc
这个可以将rust的源文件,编译成二进制的可执行文件。
用法:
rustc <source file>
Basic syntax
函数入口
main函数作为执行入口,以下是一个示例。
// This is the main function
fn main() {
// Statements here are executed when the compiled binary is called
// Print text to the console
println!("Hello World!");
}
格式化输出
- format!
用于输出格式化文本到String。
- print!
类似format!,并且文本会被打印到控制台(io::stdout)。
- println!
类似print!,并且会在会在打印后自动添加换行控制符。
- eprint!
类似format!,并且文本会被输出到标准错误流(io::stderr)。
- eprintln!
类似eprint!,并且会在会在打印后自动添加换行控制符。
std::fmt包含很多控制文本显示的方式,以下是两种重要的方式。
-
fmt::Debug: 使用标记(占位符),格式化文本以便调试。{:?} -
fmt::Display: 使用标记(占位符),以更加有好的方式进行文本格式化。{}
fmt::Display实现的ToString方式,会自动将类型转换成String。
注释
普通注释
// 这种注释是单行注释,在这一行的内容都会被编译器忽视
/*
这种注释是多行注释,在这个区域内的内容,都会被编译器忽视
*/
文档注释
/// 以下的项将会用于产生库文档条目
//! 为闭包产生库文档条目
数据类型
数据类型
- 整型:
i8,i16,i32,i64,i128andisize(pointer size) - 无符号整型:
u8,u16,u32,u64,u128andusize(pointer size) - 浮点类型:
f32,f64 char:Unicode scalar values like 'a', 'α' and '∞' (4 bytes each)bool取值 true 或者 false- 单元(unit)类型
(),它唯一的值就是空元组: ()
组合类型
arrays,数组类型,类似 [1, 2, 3]tuples,元组类型,类似 (1, true)
如何为变量声明类型
let logical: bool = true;
let a_float: f64 = 1.0;
// Or a default will be used.
let default_float = 3.0; // `f64`
let default_integer = 7; // `i32`
类似上面这样。
元组拆分
let cat = ("Furry McFurson", 3.5);
let (name, age) = cat;
元组索引
let numbers = (1, 2, 3);
println!("The second number is {}", numbers.1);
常量和变量
只用let声明的都是常量。
使用let mut声明的都是变量。
三元运算符的变化
return if a > b {a} else {b};
类似这样
数组切片
let a = [1, 2, 3, 4, 5];
let nice_slice = &a[1..4];
类似这样,分割出了[2, 3, 4]
注意!切片中的数字表示在数组指定下标处前面进行切割,所以a[4]前面切割,就把4和5分离了。
字符串
&str
字符串字面量&str是会在rust编译时就知道其值的字符串类型。
在定义元组、结构体是,需要注意&str的生命周期!
struct ColorClassicStruct<'a> {
// TODO: Something goes here
name: &'a str,
hex: &'a str
}
struct ColorTupleStruct<'a>(/* TODO: Something goes here */&'a str, &'a str);
一半会在结构体或元组后用类似<'a>的标记进行生命周期定义。
String
这是标准库中的一种字符串,可以使用String::from(<some data>)进行转换。
结构体
结构体更新语法,即只更新部分数据,但是大部分数据和另一个结构体相同时。
let your_order = Order {
name: String::from("Hacker in Rust"),
count: 1,
..order_template
};
例如以上这样,以order_template为模板,只改变name和count创建结构体。
深入学习
以上基本是根据其他语言进行的快速学习内容
Rust 特点
设计哲学
- 内存安全
- 零成本抽象
- 实用性
内存安全
遇到内存错误的一些情况
- 使用空指针
- 使用未初始化内存
- 使用野指针(悬垂指针)
- 缓冲区溢出(比如数组越界)
- 重复释放内存
Rust的做法
建立严格的安全内存管理模型
- 所有权系统。每个被分配的内存都有一个独占其所有权的指针,当指针被销毁时,对应的内存随之释放。
- 借用和生命周期。每个变量都具有生命周期,当生命周期结束后,变量会自动释放。如果是借用,则可以通过标记生命周期参数供编译器检查的方式,防止出现悬垂指针,也就是释放后使用的情况。
其中所有权系统还包括了从现代C++那里借鉴的RA ii 机制,这是Rust 无GC 但是可以安全管理内存的基石。
建立了安全内存管理模型之后,再用类型系统表达出来即可。Rust 从Haskell 的类型系统那里借鉴了以下特性:
-
没有空指针
-
默认不可变
-
表达式
-
高阶函数
-
代数数据类型
-
模式匹配
-
泛型
-
trait 和关联类型
-
本地类型推导
为了实现内存安全, Rust 还具备以下独有的特性:
- 仿射类型( Affine Type ) ,该类型用来表达Rust 所有权中的Move 语义。
- 借用、生命周期。
零成本抽象
指的是rust的抽象表达能力相比其他语言(比如Ruby)毫不逊色,并且完全不牺牲性能。
实用性
Rust将错误处理机制分为三类,失败、错误和异常,针对不同类别进行不同的处理,减少了异常处理的性能开销。
- 对于失败的情况,可以使用断言工具。
- 对于错误, Rust 提供了基于返回值的分层错误处理方式,比如Option<T>可以用来处理可能存在空值的情况, 而Result<T>就专门用来处理可以被合理解决并需要传播的错误。
- 对于异常, Rust 将其看作无法被合理解决的问题, 提供了线程恐慌机制,在发生异常的时候,线程可以安全地退出。
Rust 语言分成Safe Rust 和Unsafe Rust 两部分。其中Unsafe Rust 专门和外部系统打交道,比如操作系统内核。原因是Rust 编译器的检查和跟踪是有能力范围的,外部其他语言接口的安全状态只能靠开发者自己来保证安全。
C++的RAII机制,必须将资源封装到一个类中,并且创造析构函数才能使用RAII机制
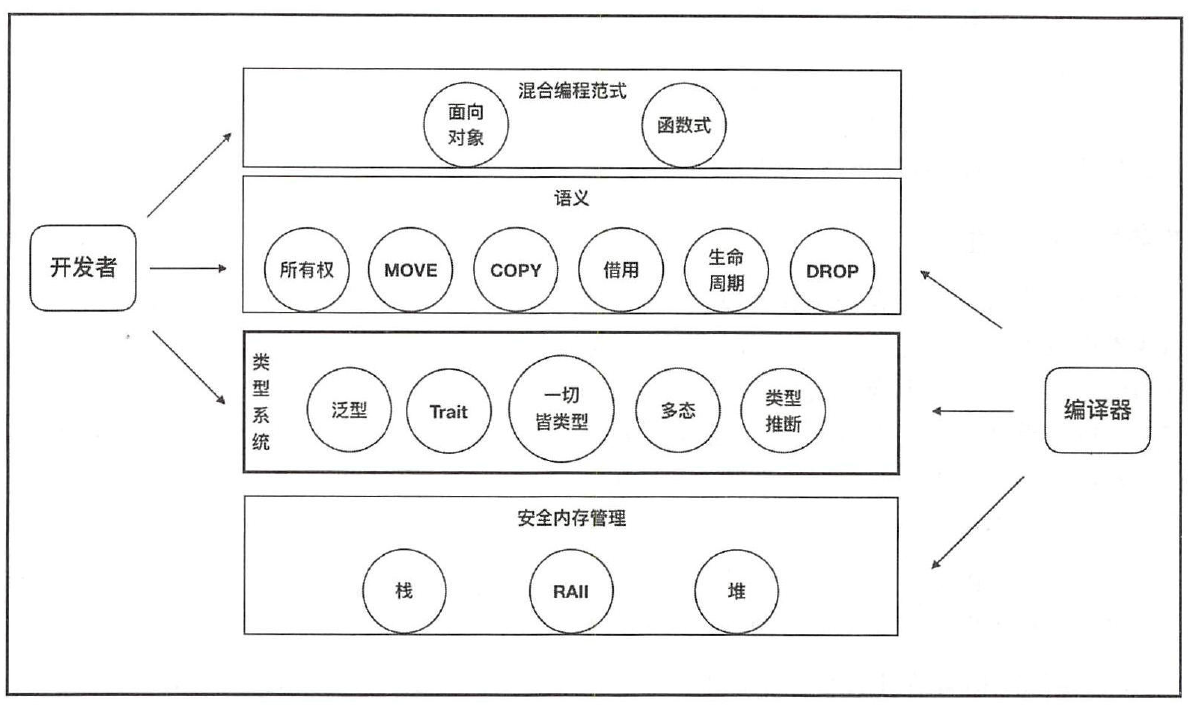
语言架构
-
最底层是安全内存管理层, 该层主要是涉及内存管理相关的概念。
-
倒数第二层是类型系统层, 该层起到承上启下的作用。类型系统层承载了上层的所有权系统语义和混合编程范式,赋予了Rust 语言高级的抽象表达能力和安全性。同时,还保留了对底层代码执行、数据表示和内存分配等操作的控制能力。
Rust编译过程
Rust 编译器是一个LLVM 编译前端,它将代码编译为LLVM IR , 然后经过LLVM 编译为相应的平台目标。
Rust 源码经过分词和解析,生成A ST C 抽象语法树) 。然后把A ST 进一步简化处理为HIR CHigh-l evel IR ),目的是让编译器更方便地做类型检查。HIR 会进一步被编译为MIR( Middle IR ) ,这是一种中间表示,它在Rustl.12 版本中被引入, 主要用于以下目的。
- 缩短编译时间。MIR 可以帮助实现增量编译,当你修改完代码重新编译的时候, 编译器只计算更改过的部分,从而缩短了编译时间。
- 缩短执行时间。MIR 可以在LLVM 编译之前实现更细粒度的优化,因为单纯依赖LLVM 的优化粒度太粗,而且Rust 无法控制,引入MIR 就增加了更多的优化空间。
- 更精确的类型检查。MIR 将帮助实现更灵活的借用检查,从而可以提升Rust 的使用体验。
最终, MIR 会被翻译为LLVM IR , 然后被LLVM 的处理编译为能在各个平台上运行的目标机器码。
Rust语言
语言规范
Rust 语言规范主要由Rust语言参考(The Rust Reference)和RFC 文档共同构成。
Rust语言参考包括三类内容:
- 对每种语言结构及其用法的描述。
- 对内存模型、并发模型、链接、调试等内存的描述。
- 影响语言设计的基本原理和参考。
编译器
Rust 是一门静态编译型语言。Rust 官方的编译器叫rustc ,负责将Rust 源代码编译为可执行文件或其他库文件( .a 、.so 、. lib 、.dll 等) 。
支持交叉编译,多平台运行,代码最终被翻译为LLVM IR。
核心库
核心库不依赖于操作系统和网络相关功能的库,可以通过在模块顶部引入#![no_std]来使用核心库。
核心库包括以下部分:
- 基础的trait ,如Copy 、Debug 、Display 、Option 等。
- 基本原始类型,如bool、char 、i8/u8 、il6/u16 、i32/u32 、i64/u64 、isize/usize 、f32/f64 、str、array 、slice 、tuple 、pointer 等。
- 常用功能型数据类型,满足常见的功能性需求,如String 、Vee 、HashMap 、Re 、Arc 、Box 等。
- 常用的宏定义,如println! 、assert!、panic!、vec! 等。
标准库
- 与核心库-样的基本trait、原始数据类型、功能型数据类型和常用宏等,以及与核心库几乎完全一致的API。
- 并发、I/O 和运行时。例如线程模块、用于消息传递的通道类型、Sync trait 等并发模块,文件、T CP 、UDP 、管道、套接字等常见IIO 。
- 平台抽象。OS 模块提供了许多与操作环境交互的基本功能,包括程序参数、环境变量和目录导航:路径模块封装了处理文件路径的平台特定规则。
- 底层操作接口,比如std::mem、std::ptr 、std: :in trinsics 等,操作内存、指针、调用编译器固有函数。
- 可选和错误处理类型O ption 和Resu l t ,以及各种选代器等。
包管理器
把按一定规则组织的多个rs 文件编译后就得到一个包( crate )。包是Rust 代码的基本编译单元,也是程序员之间共享代码的基本单元。
Rust 社区的公开第三方包都集中在crates . io 网站上面,它们的文档被自动发布到docs.rs网站上。
cargo可任意创建一个完整的项目工程。
cargo new bin_crate
cargo new --lib lib_crate
加上--lib参数表示用于编写库。
通过cargo build和cargo run可以分别对项目进行编译和运行。
语句与表达式
Rust 中的语法可以分成两大类:语句( Statement ) 和表达式( Expression )。语句是指要执行的一些操作和产生副作用的表达式。表达式主要用于计算求值。
语句又分为两种: 声明语句( Declaration statement )和表达式语句( Expression statement ) 。
- 声明语句,用于声明各种语言项Cl tem ),包括声明变量、静态变量、常量、结构体、函数等,以及通过extern 和use 关键字引入包和模块等。
- 表达式语句,特指以分号结尾的表达式。此类表达式求值结果将会被舍弃, 并总是返回单元类型() 。
Rust 会为每个crate 都自动引入标准库模块,除非用#![no_std]属性指明不用标准库。
变量与绑定
let 创建的变量一般称为绑定( Binding ),它表明了标识符( Identifier ) 和值( Value )之间建立的一种关联关系。
位置表达式和值表达式
Rust 中的表达式一般可以分为位置表达式( Place Expression )和值表达式( Value Expression )。在其他语言中, 一般叫作左值( LValue )和右值(RValue ) 。
位置表达式就是表示内存位置的表达式。分别有以下几类:
- 本地变量
- 静态变量
- 解引用(*expr)
- 数组索引(expr[expr])
- 字段引用(expr.field)
- 位置表达式组合
通过位置表达式可以对某个数据单元的内存进行读写。主要是进行写操作,这也是位置表达式可以被赋值的原因。
除此之外的表达式就是值表达式。值表达式一般只引用了某个存储单元地址中的数据。它相当于数据值,只能进行读操作。
从语义角度来说,位置表达式代表了持久性数据,值表达式代表了临时数据。
表达式的求值过程在不同的上下文中会有不同的结果。求值上下文也分为位置上下文(Place Context )和值上下文( Value Context ) 。下面几种表达式属于位置上下文:
- 赋值或者复合赋值语句左侧的操作数。
- 一元引用表达式的独立操作数。
- 包含隐式借用(引用)的操作数。
- match 判别式或let 绑定右侧在使用ref 模式匹配的时候也是位置上下文。
除了上述几种情况,其余表达式都属于值上下文。值表达式不能出现在位置上下文中。
不可变绑定和可变绑定
使用let 关键字声明的位置表达式默认不可变,为不可变绑定。通过mut 关键字,可以声明可变的位置表达式,即可变绑定。可变绑定可以正常修改和赋值。
从语义上来说, let 默认声明的不可变绑定只能对相应的存储单元进行读取,而let mut声明的可变绑定则是可以对相应的存储单元进行写入的。
所有权与引用
当位置表达式出现在值上下文中时,该位置表达式将会把内存地址转移给另外一个位置表达式, 这其实是所有权的转移。
在语义上,每个变量绑定实际上都拥有该存储单元的所有权, 这种转移内存地址的行为就是所有权( OwnerShip )的转移,在Rust 中称为移动( Move )语义,那种不转移的情况实际上是一种复制( Copy ) 语义。
有时候并不需要转移所有权。Rust 提供引用操作符( & ), 可以直接获取表达式的存储单元地址,即内存位置。可以通过该内存位置对存储进行读取。
通过println ! 宏指定{:p}格式,可以打印变量的指针地址,也就是内存地址。
函数与闭包
函数定义
函数是通过关键字fn 定义的。
例如函数签名pub fn fizz_ buzz(num: i32) - > String 清晰地反映了函数的类型约定:传入i32 类型,返回String 类型。Rust 编译器会严格遵守此类型的契约,如果传入或返回的不是约定好的类型,则编译时会报错。
return 表达式用于退出一个函数, 并返回一个值。但是如果return 后面没有值,就会默认返回单元值。
作用域与生命周期
Rust 语言的作用域是静态作用i茧,即词法作用域( Lexical Scope )。由一对花括号来开辟作用域, 其作用域在词法分析阶段就巳经确定了, 不会动态改变。
这种连续用let定义同名变量的做法叫变量遮蔽C Variable Shadow )。
函数指针
pub fn math (op: fn (i 32 , i32 ) -> i32 , a : i32 , b : i32)
fn (i 32 , i32 ) -> i32 这样的类型就是函数指针
CTFE机制
编译时函数执行(Compile-Time Function Execution, CTFE )的能力。
在编译期求值。
Rust 中的CTFE 是由miri 来执行的。miri 是一个MIR 解释器,目前己经被集成到了Rust编译器rustc 中。Ru st 编译器目前可以支持的常量表达式有: 字面量、元组、数组、字段结构体、枚举、只包含单行代码的块表达式、范围等。
闭包
闭包也叫匿名函数。闭包有以下几个特点:
- 可以像函数一样被调用。
- 可以捕获上下文环境中的自由变量。
- 可以自动推断输入和返回的类型。
闭包和函数有一个重要的区别,那就是闭包可以捕获外部变量, 而函数不可以。
Rust 中闭包实际上就是由一个匿名结构体和trait 来组合实现的。
注意:
fn two_times_impl() -> impl Fn(i32) ->i32 {
let i = 2;
mov |j| J * i
}
在函数two_times_impl 中最后返回闭包时使用了move 关键字。这是因为在一般情况下,闭包默认会按引用捕获变量。如果将此闭包返回,则引用也会跟着返回。但是在整个函数调用完毕之后,函数内的本地变量i就会被销毁。那么随闭包返回的变量i的引用,也将成为悬垂指针。Rust 是注重内存安全的语言, 绝对不会让这种事情发生。所以如果不使用move 关键字,编译器会报错。使用move 关键字, 将捕获变量i 的所有权转移到闭包中,就不会按引用进行捕获变量, 这样闭包才可以安全地返回。
流程控制
条件表达式
表达式一定会有值,所以i f 表达式的分支必须返回同一个类型的值才可以。这也是Rust没有三元操作符?: 的原因。i f 表达式的求值规则和块表达式一致。
循环表达式
Rust 中包括三种循环表达式: while 、loop 和for... in 表达式, 其用法和其他编程语言相应的表达式基本类似。
for. .. in 表达式本质上是一个选代器。其中1..101 是一个Range 类型,它是一个迭代器。for 的每一次循环都从迭代器中取值, 当选代器中没有值的时候, for循环结束。
当需要使用无限循环的时候, 请务必使用loop 循环,避免使用while true 循环。
match 表达式与模式匹配
在Rust 语言中, match 分支使用了模式匹配( Pattern Matching )技术。
在Rust 语言中, match 分支左边就是模式,右边就是执行代码。模式匹配同时也是一个表达式,和if 表达式类似,所有分支必须返回同一个类型。但是左侧的模式可以是不同的。
使用操作符@可以将模式中的值绑定给一个变量, 供分支右侧的代码使用,这类匹配叫绑定模式( Binding Mode )。match 表达式必须穷尽每一种可能,所以一般情况下,会使用通配符来处理剩余的情况。
if let 和while let 表达式
和match 表达式相似, if let左侧为模式,右侧为要匹配的值。
while let和match类似,不过它是循环匹配。
基本数据类型
布尔类型
Rust 内置了布尔类型, 类型名为bool 。bool类型只有两个值一一true 和false。
任意一个比较操作都会产生bool类型也可以通过as 操作符将bool类型转换为数字0和1 。但要注意, Rust 并不支持将数字转换为bool类型。
基本数字类型
Rust 提供的基本数字类型大致可以分为三类: 固定大小的类型、动态大小的类型和浮点数。
固定大小的类型包括无符号整数( Unsigned Integer )和符号整数( Signed Integer )
- 无符号整数
- u8
- u16
- u32
- u64
- u128
- 符号整数
- i8
- i16
- i32
- i64
- i128
- 动态大小类型
- usize,占用4个或8个字节, 具体取决于机器的字长。
- isize,占用4 个或8个字节, 同样取决于机器的字长。
- 浮点数类型
- f32
- f64
数字字面量后面可以直接使用类型后缀,比如42u32,代表这是一个u32 类型。如果不加后缀或者没有指定类型, Rust编译器会默认推断数字为i32类型。
可以用前缀0x 、0o 和0b 分别表示十六进制、八进制和l 二进制类型。
Rust 中也可以写字节字面量,比如以b 开头的字符b'*', 它实际等价于42u8.
字符类型
在Rust 中, 使用单引号来定义字符( Char )类型。字符类型代表的是一个Unicode 标量值, 每个字符占4 个字节。
字符也可以使用ASCII 码和Unicode 码来定义,'2A' 为ASCII 码表中表示符号'*'的十六进制数, 格式为’\xHH’ 。’ 151 ’是U nicod e 十六进制码,格式为’\u{HHH} ’
可以使用as 操作符将字符转为数字类型。
数组类型
数组(Array)是Rust内建的原始集合类型,数组的特点为:
- 数组大小固定。
- 元素均为同类型。
- 默认不可变。
数组的类型签名为[ T; N ] 。T 是一个泛型标记,它代表数组中元素的某个具体类型。N 代表数组的长度,是一个编译时常量,必须在编译时确定其值。
类型范围
Rust 内置了范围( Range ) 类型,包括左闭右开和全闭两种区间。
(1 .. 5 )表示左闭右开区间,( 1 .. =5)则表示全闭区间。它们分别是std : :ops: :Range 和std: :ops: : Rangelnclusive 的实例。
范围自带了一些方法,比如sum ,可以为范围中的元素进行求和。并且每个范围都是一个法代器,可以直接使用for 循环进行打印。请注意两种区间的不同。
切片类型
切片( Slice )类型是对一个数组(包括固定大小数组和动态数组) 的引用片段。
在底层,切片代表一个指向数组起始位置的指针和数组长度。用[T]类型表示连续序列,那么切片类型就是&[T]和&mut[T]。
str字符串类型
Rust 提供了原始的字符串类型凹,也叫作字符串切片。它通常以不可变借用的形式存在,即&str。出于内存安全的考虑, Rust 将字符串分为两种类型, 一种是固定长度字符串,不可随便更改其长度,就是str 字符串;另一种是可增长字符串,可以随意改变其长度,就是String字符串。
本质上, 字符串字面量也属于str 类型,只不过它是静态生命周期字符串& ’ static str。所谓静态生命周期,可以理解为该类型字符串和程序代码一样是持续有效的。
str 字符串类型由两部分组成:指向字符串序列的指针和记录长度的值。可以通过str 模块提供的as_ptr 和len方法分别求得指针和长度
Rust 中的字符串本质上是一段有效的UTF8 字节序列。
可以将一段字节序列转换为s位字符串。因为整个过程并没有验证字节序列是否为合法的UTF8字符串,所以需要放到unsafe 块中执行整个转换过程。如果开发者看到unsafe 块, 就意味着Rust编译器将内存安全交由开发者自行负责了。
原生指针
我们将可以表示内存地址的类型称为指针。Rust 提供了多种类型的指针,包括引用( Reference)、原生指针( Raw Pointer )、函数指针( fn Pointer)和智能指针( Smart Pointer )。
Rust 可以划分为Safe Rust 和Unsafe Rust两部分,引用主要应用于Safe Rust 中。在Safe Rust中, 编译器会对引用进行借用检查,以保证内存安全和类型安全。
原生指针主要用于Unsafe Rust 中。直接使用原生指针是不安全的,比如原生指针可能指向一个Null ,或者一个己经被释放的内存区域,因为使用原生指针的地方不在Safe Rust 的可控范围内,所以需要程序员自己保证安全。Rust 支持两种原生指针: 不可变原生指针*const T和可变原生指针*mut T 。
never类型
Rust 中提供了一种特殊数据类型, never 类型, 即! 。该类型用于表示永远不可能有返回值的计算类型,比如线程退出的时候, 就不可能有返回值。
现在还是实验阶段,所以需要加上#![feature(never_ type)]
let x : ! = {
return 11
};
这里就是定义了never类型。
never 类型是可以强制转换为其他任何类型的。
复合数据类型
元组
元组( Tuple )是一种异构有限序列,形如何(T, U ,M,N) 。所谓异构,就是指元组内的元素可以是不同类型的;所谓有限,是指元组有固定的长度。
因为let 支持模式匹配,所以可以用来解构元组。
let (x, y) = (1, 2);
当元组中只有一个值的时候,需要加逗号,即(0, ), 这是为了和括号中的其他值进行区分,其他值形如(0 ) 。实际上前面函数部分讲到的单元类型就是一个空元组,即0 。
结构体
Rust 提供三种结构体:
- 具名结构体( Named-F i e ld Struct)
- 元组结构体( Tup l e - Like Struct )
- 单元结构体( Unit-Like Struct)
struct People {
name: &'static str,
gender: u32,
}
这种就是具名结构体。
People 结构体上方的# [ derive(Debug, PartialEq)] 是属性,可以让结构体自动实现Debug
trait和PartialEq trait , 它们的功能是允许对结构体实例进行打印和比较。
在Rust中,函数和方法是有区别的。如果不是在impl块里定义的函数,就是自由函数。而在impl 块中定义的函数被称为方法,这和面向对象有点渊源。
除了具名结构体, Rust 中还有一种结构体,它看起来像元组和具名结构体的混合体,叫元组结构体,其特点是,字段没有名称,只有类型。
struct Color(i32, i32, i32);
当一个元组结构体只有一个字段的时候,我们称之为New Type 模式。
之所以称为New Type模式, 是因为相当于把u32 类型包装成了新的Integer 类型。
struct Integer(u32);
Rust 中可以定义一个没有任何字段的结构体,即单元结构体。
struct Empty;
等价于由uct Empty {} 。单元结构体实例就是其本身。
在Release 编译模式下,单元结构体实例会被优化为同一个对象。而在Debug模式下,则不会进行这样的优化。
单元结构体与New Typ e 模式类似,也相当于定义了一个新的类型。单元结构体一般用于一些特定场景,标准库中表示全范围()的RangeFull , 就是一个单元结构体。
枚举体
枚举体( Enum ,也可称为枚举类型或枚举) ,该类型包含了全部可能的情况,可以有效地防止用户提供无效值。在Rust 中, 枚举类型可以使用enum 关键字来定义, 并且有三种形式,其中一种是无参数枚举体。
enum Number {
Zero, One, Two
}
Rust 也可以编写像C 语言中那种形式的枚举体,称之为类C 枚举体。
enum Color {
Red = 0xff0000,
Green = 0x00ff00,
Blue = 0x0000ff,
}
Rust 还支持携带类型参数的枚举休,也就是我们要讲的第三种枚举体。
enum IpAddr {
V4(u8, u8, u8, u8),
V6(String),
}
枚举体在Ru st 中属于非常重要的类型之一。一方面它为编程提供了很多方便,另一方面,它保证了Rus t 中避免出现空指针。
Option 枚举类型, 该类型表示有值和无值两种情况。其中Some(i32)代表有i32 类型的值,而None 代表无任何值。
在main 函数中, 定义了绑定s 的值为Some(42 ) 。因为这里的值是确定的,所以可以使用unwrap 方法将Some(42) 中的数字42 取出来。如果在不确定的情况下使用unwrap ,可能会导致运行时错误。我们可以使用match 匹配来枚举这两种情况,并分别处理。
常用集合类库
在Rust 标准库s td : :collections 模块下有4 种通用集合类型,分别如下。
- 线性序列: 向量(Vue)、双端队列(VecDeque)、链表(LinkedList)。
- Key-Value 映射表: 无序哈希表(HashMap)、有序哈希表(BTreeMap)。
- 集合类型: 无序集合(HashSet)、有序集合(BTreeSet)。
- 优先队列: 二叉堆( BinaryHeap )。
线性序列:向量
向量也是一种数组,和基本数据类型中的数组的区别在于,向量可动态增长。
vec!是一个宏,用来创建向量字面量。宏语句可以使用圆括号,也可以使用中括号和花括号,一般使用中括号来表示数组。可以使用push 方法往向量数组中添加新的元素。
Rust 对向量和l数组都会做越界检查,以保证安全。
初始化方式
let mut v1 = vec![];
let mut v2 = vec![0; 10];
let mut v3 = Vue::new();
线性序列:双端队列
双端队列( Double-ended Queue , 缩写为Deque )是一种同时具有队列(先进先出)和战( 后进先出)性质的数据结构。双端队列中的元素可以从两端弹出,插入和删除操作被限定在队列的两端进行。
Rust 中的VecDeque 是基于可增长的RingBuffer 算法实现的双端队列。
需要通过use 关键字引入std: :collections:: VecDeque ,因为VecDeque<T>并不会像Vec<T>那样被自动引入。
双端队列VecDeque 实现了两种push 方法, push_front和push_back。push_front 的行为像栈, push_back 的行为像队列。通过get 方法加索引值可以获取队列中相应的值。
线性序列:链表
Rust提供的链表是双向链表,允许在任意一端插入或弹出元素。但是通常最好使用Vec或VecDeque 类型, 因为它们比链表更加快速,内存访问效率更高,并且可以更好地利用CPU缓存。
使用use 显式引入std : :collections: :LinedList 。因为是双向列表,所以提供了push_back 和push_front 两类方法,方便操作此链表。也提供了append 方法, 可以用来连接两个链表。
Key-Value 映射表: HashMap和BTreeMap
Rust 集合模块一共为我们提供了两个Key-Value哈希映射表,这两种类型的区别之一是, Hash Map 是无序的, BTreeMap 是有序的。它们的类型签名分别是HashMap<K, V>和BTreeMap < K, V>。
use std::collections::BTreeMap 和use std::collections::HashMap 。通过内置的new 方法,可以创建相应的实例。然后通过insert 方法插入键值对。
集合: HashSet 和BTreeSet
HashSet <K>和BTreeSet<K>其实就是HashMap <K, V> 和BTreeMap < K, V >把Value 设置为空元组的特定类型,等价于HashSet <K, ()>和BTreeSet < K, ()>。所以这两种集合类型的特性大概如下:
- 集合中的元素应该是唯一的,因为是Key -Value 映射表的Key 。
- 同理,集合中的元素应该都是可哈希的类型。
- HashSet 应该是无序的, BTreeSet 应该是有序的。
优先队列: BinaryHeap
Rust 提供的优先队列是基于二叉最大堆( Binary Heap ) 实现的。
使用BinaryHeap: :new 创建了空的最大堆。使用peek 方法可以取出堆中的最大值。没有值的时候是None。
智能指针
Rust 中的值默认被分配到桔内存。可以通过Box <T>将值装箱(在堆内存中分配) 。Box< T> 是指向类型为T 的堆内存分配值的智能指针。当Box < T>超出作用域范围时, 将调用其析构函数, 销毁内部对象, 并自动释放堆中的内存。可以通过解引用操作符来获取Box< T >中的T。
Box <T >的行为像引用,并且可以自动释放内存,所以我们称其为智能指针。通过Box<T> ,开发者可以方便无痛地使用堆内存, 并且无须手工释放堆内存, 可以确保内存安全。
泛型和trait
- trait 是Rust 唯一的接口抽象方式。
- 可以静态生成, 也可以动态调用。
- 可以当作标记类型拥有某些特定行为的“ 标签” 来使用。
trait 是对类型行为的抽象。
泛型
Ru s t 标准库中定义了很多泛型类型,包括Option< T> 、Vec <T> 、H as hM a p< K, V> 以及Box <T >等。其中Option< T>就是一种典型的使用了泛型的类型.
类似<T : Debug>是增加了trait 限定的泛型,也就是说,只有实现了Debug trait 的类型才适用。只有实现了Debug trait 的类型才拥有使用” {:?} ”格式化打印的行为。
trait
trait 和类型的行为有关。
在Rust 中, trait 是唯一的接口抽象方式。使用trait 可以让不同的类型实现同一种行为,也可以为类型添加新的行为。
Rust 通过trait 将类型和行为明确地进行了区分,充分贯彻了组合优于继承和面向接口编程的编程思想。
可以使用#[derive (Debug) I 属性帮助开发者自动实现Debug trait 。这类属性本质上属于Rust 中的一种宏。
错误处理
Rust 中的错误处理是通过返回Res ult<T, E>类型的方式进行的。Result<T, E >类型是Option <T>类型的升级版本。
Option< T>类型表示值存在的可能性, Re sult <T, E >类型表示锚院的可能性,其中泛型E代表Error 。
注释和打印
Rust 文档的哲学是:代码即文档,文档即代码。
普通注释// commit、/* commit */
文档注释/// 一般在函数或结构体上面,说明函数或结构体 、//! 一般在模块文件头部,说明整个模块功能
println!宏中的格式化形式列表如下:
- nothing 代表Display ,比如println !("{}", 2) 。
- ?代表Debug
- o代表八进制
- x代表十六进制小写
- X代表十六进制大写
- p 代表指针
- b 代表二进制
- e 代表指数小写
- E 代表指数大写
类型系统
类型大小
Rust编译器需要事先知道类型的大小,才能分配合理的内存。
Rust 中绝大部分类型都是在编译期可确定大小的类型( Sized Type)
Rust 也有少量的动态大小的类型( Dynamic Sized Type, DST ),比如str 类型的字符串字面量, 编译器不可能事先知道程序中会出现什么样的字符串,所以对于编译器来说, str 类型的大小是无法确定的。对于这种情况, Rust 提供了引用类型,因为引用总会有固定的且在编译期己知的大小。字符串切片&str 就是一种引用类型,它由指针和长度信息组成。
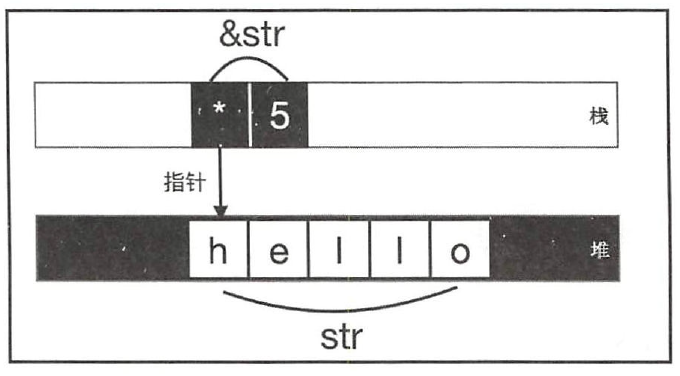
&str 存储于栈上, str 字符串序列存储于堆上。
&str 由两部分组成:指针和长度信息。
这种包含了动态大小类型地址信息和携带了长度信息的指针,叫作胖指针( Fat Pointer ) ,所以&str 是一种胖指针。
零大小类型
除了可确定大小类型和DST 类型, Rust 还支持零大小类型( Zero Sized Type, ZST) ,比如单元类型和单元结构体, 大小都是零。
单元类型和单元结构体大小为零,由单元类型组成的数组大小也为零。ZST 类型的特点是,它们的值就是其本身,运行时并不占用内存空间。
底类型
底类型( Bottom Type )是源自类型理论的术语, 它其实是之前介绍过的never 类型。
特点是:
- 没有值。
- 是其他任意类型的子类型。
如果说ZST 类型表示“空”的话,那么底类型就表示“无” 。底类型无值,而且它可以等价于任意类型, 有点无中生有之意。
Rust 中的底类型用叹号(!) 表示。此类型也被称为Bang Type 。Rust 中有很多种情况确实没有值,但为了类型安全,必须把这些情况纳入类型系统进行统一处理。这些情况包括:
- 发散函数( Diverging Function )
- continue 和break 关键字
- loop 循环
- 空枚举,比如enum Void{}
Rust 中if 语句是表达式, 要求所有分支类型一致, 但是有的时候,分支中可能包含了永远无法返回的情况,属于底类型的一种应用。
空枚举, 比如enum Void {},完全没有任何成员,因而无法对其进行变量绑定,不知道如何初始化并使用它,所以它也是底类型。
Rust 中使用Result 类型来进行错误处理, 强制开发者处理Ok 和Err两种情况,但是有时可能永远没有Err, 这时使用enum Void {}就可以避免处理Err的情况。当然这里也可以用if let语句处理,但是这里为了说明空枚举的用法故意这样使用。
类型推导
Rust 只能在局部范围内进行类型推导。
Turbofish 操作符
使用了parse:: <i32>(),这种标注类型(::<>)的形式就叫作turbofish 操作符。
在用Rust 编程的时候, 应尽量显式声明类型,这样可以避免一些麻烦。
泛型
泛型( Generic )是一种参数化多态。使用泛型可以编写更为抽象的代码, 减少工作量。
泛型函数
fn foo<T>(x: T) -> T {
return x;
}
泛型只有被声明之后才可以被使用。
Rust 中的泛型属于静多态,它是一种编译期多态。在编译期,不管是泛型枚举, 还是泛型函数和泛型结构体,都会被单态化( Monomorphization ) 。单态化是编译器进行静态分发的一种策略。 单态化意昧着编译器要将一个泛型函数生成两个具体类型对应的函数,
泛型及单态化是Rust 的最重要的两个功能。单态化静态分发的好处是性能好, 没有运行时开销;缺点是容易造成编译后生成的二进制文件膨胀。
泛型返回值自动推导
trait Inst {
fn new(i: i32) -> Self;
}
深入trait
需要补充
从类型系统的角度来说, trait 是Rust 对Ad-hoc 多态的支持。从语义上来说, trait 是在行为上对类型的约束,这种约束可以让trait 有如下4 种用法:
- 接口抽象。接口是对类型行为的统一约束。
- 泛型约束。泛型的行为被trait 限定在更有限的范围内。
- 抽象类型。在运行时作为一种间接的抽象类型去使用, 动态地分发给具体的类型。
- 标签trait 。对类型的约束,可以直接作为一种“标签”使用。
孤儿规则:(Orphan Rule ) 。孤儿规则规定, 如果要实现某个trait ,那么该trait 和要实现该trait 的那个类型至少有一个要在当前crate 中定义。
trait 继承
Rust 不支持传统面向对象的继承,但是支持trait 继承。子trait 可以继承父trait 中定义或实现的方法。
trait 限定
Rust 中的trait 限定也是Structural Typing 的一种实现, 可以看作一种静态Duck Typing 。
Rust 编程的哲学是组合优于继承, Rust 并不提供类型层面上的继承, Rust 中所有的类型都是独立存在的,所以Rust 中的类型可以看作语言允许的最小集合,不能再包含其他子集。而trait 限定可以对这些类型集合进行组合,也就是求交集。
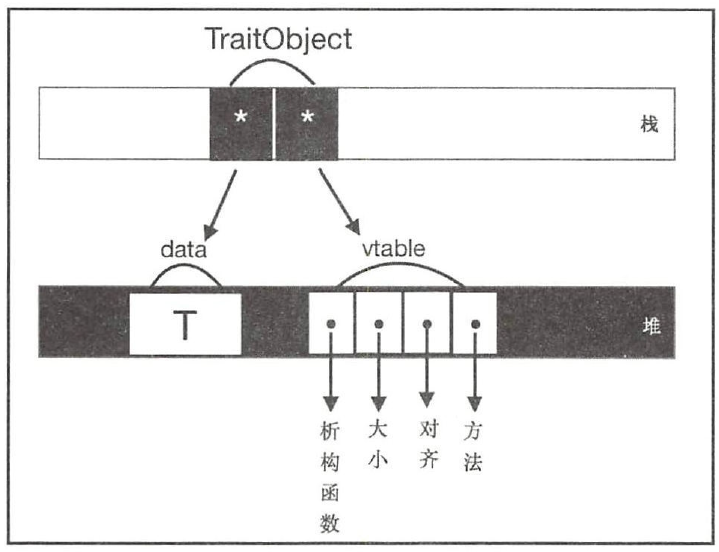
TraitObject 包括两个指针: data 指针和vtable 指针。以impl MyTrait for T 为例, data指针指向trait 对象保存的类型数据T, vtabl e 指针指向包含为T 实现的MyTrait 的Vtable( Virtual Table ) , 该名称来源于C++, 所以可以称之为虚表。虚表的本质是一个结构体, 包含了析构函数、大小、对齐和方法等信息。

在编译期, 编译器只知道TraitObject 包含指针的信息, 并且指针的大小也是确定的,并不知道要调用哪个方法。在运行期, 当有trait_object.method()方法被调用时, TraitObject 会根据虚表指针从虚表中查出正确的指针,然后再进行动态调用。这也是将trait 对象称为动态分发的原因。
当trait 对象在运行期进行动态分发时,也必须确定大小,否则无法为其正确分配内存空间。所以必须同时满足以下两条规则的trait 才可以作为trait 对象使用。
- trait 的SeIf 类型参数不能被限定为Sized 。
- trait 中所有的方法都必须是对象安全的。
当把trait 当作对象使用时,其内部类型就默认为Unsize 类型, 也就是动态大小类型,只是将其置于编译期可确定大小的胖指针背后,以供运行时动态调用。对象安全的本质就是为了让trait 对象可以安全地调用相应的方法。如果给trait 加上Self: Sized 限定,那么在动态调用trait 对象的过程中,如果碰到了Unsize 类型, 在调用相应方法时,可能引发段错误。所以,就无法将其作为trait 对象。反过来,当不希望trait 作为trait 对象时,可以使用Self: Sized 进行限定。
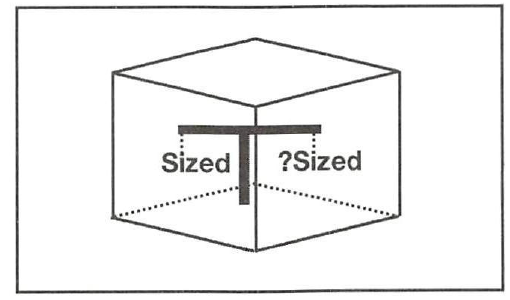
标签trait
Rust 一共提供了5 个重要的标签trait ,都被定义在标准库std : : marker 模块中。它们分别是:
- Sized trait ,用来标识编译期可确定大小的类型。
- Unsize trait , 目前该trait 为实验特性,用于标识动态大小类型CDST )。
- Copy trait ,用来标识可以按位复制其值的类型。
- Send trait , 用来标识可以跨线程安全通信的类型。
- Sync trait,用来标识可以在线程间安全共享引用的类型。
Copy 的行为是一个隐式的行为,开发者不能重载Copy 行为,它永远都是一个简单的位复制。Copy 隐式行为发生在执行变量绑定、函数参数传递、函数返回等场景中,因为这些场景是开发者无法控制的,所以需要编译器来保证。
Clone trait 是一个显式的行为,任何类型都可以实现C l one trait,开发者可以自由地按需实现Copy 行为。
并非所有类型都可以实现Copy trait 。对于自定义类型来说,必须让所有的成员都实现了Copy trait , 这个类型才有资格实现Copy trait 。
实现了Send 的类型, 可以安全地在线程间传递值,也就是说可以跨线程传递所有权。
实现了Sync 的类型, 可以跨线程安全地传递共享( 不可变)引用。
有了这两个标签trait ,就可以把Rust 中所有的类型归为两类:可以安全跨线程传递的值和引用, 以及不可以跨线程传递的值和引用。再配合所有权机制,带来的效果就是, Rust 能够在编译期就检查出数据竞争的隐患, 而不需要等到运行时再排查。
类型转换
类型转换分为隐式类型转换( Implicit Type Conversion )和显式类型转换( Explicit Type Conversion )。隐式类型转换是由编译器或解释器来完成的,开发者并未参与,所以又称之为强制类型转换( Type Coe rcion )。显式类型转换是由开发者指定的,就是一般意义上的类型转换( Type Cast )。
Deref解引用
Rust 中的隐式类型转换基本上只有自动解引用。自动解引用的目的主要是方便开发者使用智能指针。Rust 中提供的Box < T >、Rc <T>和String 等类型,实际上是一种智能指针。
自动解引用虽然是编译器来做的,但是自动解引用的行为可以由开发者来定义。
引用使用&操作符, 而解引用使用*操作符。
Deref 有一个特性是强制隐式转换,规则是这样的:如果一个类型T 实现了Deref<Target=U>, 则该类型T 的引用(或智能指针)在应用的时候会被自动转换为类型U 。
as操作符
as 操作符最常用的场景就是转换Rust 中的基本数据类型。需要注意的是, as 关键字不支持重载。
短(大小)类型转换为长(大小)类型的时候是没有问题的, 但是如果反过来,则会被截断处理。
当从有符号类型向无符号类型转换的时候, 最好使用标准库中提供的专门的方法,而不要直接使用as 操作符。
无歧义完全限定语法
为结构体实现多个trait 时,可能会出现同名的方法
消除歧义的两种办法:
- 第一种就是代码清单3 - 66 中的第2 0 行和2 1 行,直接当作tra it 的静态函数来调用,A::test()或B::test()。
- 第二种就是使用as 操作符,<S as A> ::tes t () 或<S as B>::test ()。
这两种方式叫作无歧义完全限定语法( Fully Qualified Syntax for Disambiguation ) , 曾经也有另外一个名字:通用函数调用语法C UFCS )
第二种方法的可读性更佳。
类型和子类型相互转换
as 转换还可以用于类型和子类型之间的转换。
Rust 中没有标准定义中的子类型, 比如结构体继承之类, 但是生命周期标记可看作子类型。
比如&’ static str 类型是&’ a str 类型的子类型, 因为二者的生命周期标记不同, 'a和'static都是生命周期标记,其中’a 是泛型标记, 是
&str 的通用形式, 而’ static 则是特指静态生命周期的& str 字符串。所以, 通过as 操作符转换可以将&’ static str 类型转为&’ a str 类型,
From和Into
From 和Into 是定义于std: : convert 模块中的两个trait 。它们定义了from 和into 两个方法,这两个方法互为反操作。
内部实现如下
pub trait From<T> {
fn from(T) -> Self;
}
pub trait Into<T> {
fn into(self) -> T;
}
对于类型T,如果它实现了From< U> ,则可以通过T::from(u)来生成T 类型的实例,此处u 为U 的类型实例。
对于类型T,如果它实现了lnto<U>, 则可以通过into 方法来消耗自身转换为类型U 的新实例。
关于Into 有一条默认的规则:如果类型U 实现了From<T>,则T类型实例调用into 方法就可以转换为类型U 。
例如
fn main() {
let a = "hello";
let b : String = a.into();
}
在标准库中, 还包含了Try From 和TryInto 两种trait ,是From 和Into 的错误处理版本,因为类型转换是有可能发生错误的,所以在需要进行错误处理的时候可以使用TryFrom和Try Into 。
另外,标准库中还包含了AsRef 和AsMut 两种trait , 可以将值分别转换为不可变引用和可变引用。AsRef 和标准库的另外一个Borrow trait 功能有些类似,但是AsRef 比较轻量级,它只是简单地将值转换为引用,而Borrow trait 可以用来将某个复合类型抽象为拥有借用语义的类型。
Trait系统的不足
主要有以下三点。
- 孤儿规则的局限性。
- 代码复用的效率不高。
- 抽象表达能力有待改进。
孤儿规则的局限性
在设计trait 时, 还需要考虑是否会影响下游的使用者。比如在标准库实现一些trait 时,还需要考虑是否需要为所有的T 或&'a T 实现trait。对于下游的子crate 来说,如果想要避免孤儿规则的影响,还必须使用NewType模式或者其他方式将远程类型包装为本地类型。这就带来了很多不便。
另外,对于一些本地类型, 如果将其放到一些容器中,比如Rc <T >或Option < T> , 那么这些本地类型就会变成远程类型, 因为这些容器类型都是在标准库中定义的, 而非本地。
代码复用的效率不高
重叠( Overlap )规则。该规则规定了不能为重叠的类型实现同一个trait 。
重叠类型示例
impl<T> AnyTrait for T {...}
impl<T> AnyTrait for T where T: Copy {...}
impl<T> AnyTrait for i32 {...}
上面分别为三种类型实现了Any Trait。
- T 是泛型,指代所有的类型。
- T where T: Copy 是受trait 限定约束的泛型T ,指代实现了C opy 的一部分T , 是所有类型的子集。
- i32 是一个具体的类型。
显而易见,上面三种类型发生了重叠。T 包含了T: Copy ,而T: Copy 包含了i32 。这违反了重叠规则,所以编译会失败。这种实现trait 的方式在Rust 中叫覆盖式实现( Blanket Impl ) 。
重叠规则和孤儿规则一样,都是为了保证trait 一致性,避免发生混乱, 但是它也带来了一些问题,主要包括以下两个方面:
- 性能问题
- 代码很难重用
重叠规则严重影响了代码的复用。
那么为了缓解重叠规则带来的问题, Rust 引入了特化(Specialization ) 。特化功能暂时只能用于impl 实现,所以也称为impI特化。
抽象表达能力有待改进
选代器在Rust 中应用广泛,但是它目前有一个缺陷:在迭代元素的时候,只能接值进行迭代,有的时候必须重新分配数据,而不能通过引用来复用原始的数据。
比如标准库中的
std: :io: :Lines 类型用于按行读取文件数据, 但是该实现法代器只能读一行数据分配一个新的String ,而不能重用内部缓存区。这样就影响了性能。
泛型关联类型( Generic Associated Type, GAT),可以支持引用类型,重用内部缓存区,而不需要重新分配新的内存。
内存管理
转移所有权产生了未初始化变量
当将一个己初始化的变量y绑定给另外一个变量y2时, Rust 会把变量y 看作逻辑上的未初始化变量。
RAII也有另外一个别名, 叫作用域界定的资源管理( Scope-Bound Resource Management, SBRM )。
内存安全的定义
不出现以下问题即为内存安全
- 使用未定义内存。
- 空指针。
- 悬垂指针。
- 缓冲区溢出。
- 非法释放未分配的指针或己经释放过的指针。
Rust 中的变量必须初始化以后才可使用,否则无法通过编译器检查。所以,可以排除第一种情况, Rust 不会允许开发者使用未定义内存。